

What are large language models (LLMs)?
Large Language Models (LLMs) are a type of artificial intelligence model that uses vast amounts of text data to understand and generate human language. These models are designed to process and generate text in a way that mimics human language patterns and structures. LLMs are trained on massive datasets that include a wide range of text sources, such as books, articles, websites, and other written content, to develop a deep understanding of language use.
One of the key features of LLMs is their ability to learn from context, allowing them to generate coherent and contextually relevant text. These models utilize a technique known as deep learning, which involves training neural networks with multiple layers to analyze and process input data. This enables LLMs to make predictions and generate text based on the patterns and relationships they have learned from the training data.
Larger language models, such as GPT-3 (Generative Pre-trained Transformer 3), have billions of parameters and are capable of achieving impressive levels of fluency and coherence in their text generation. These models have been used in a variety of applications, including language translation, content generation, chatbots, and more. LLMs have shown great potential in improving natural language processing tasks and have generated significant interest and research in the field of artificial intelligence.
Overall, large language models represent a significant advancement in the development of AI technology, offering powerful tools for understanding and generating human language in a way that was previously unthinkable.
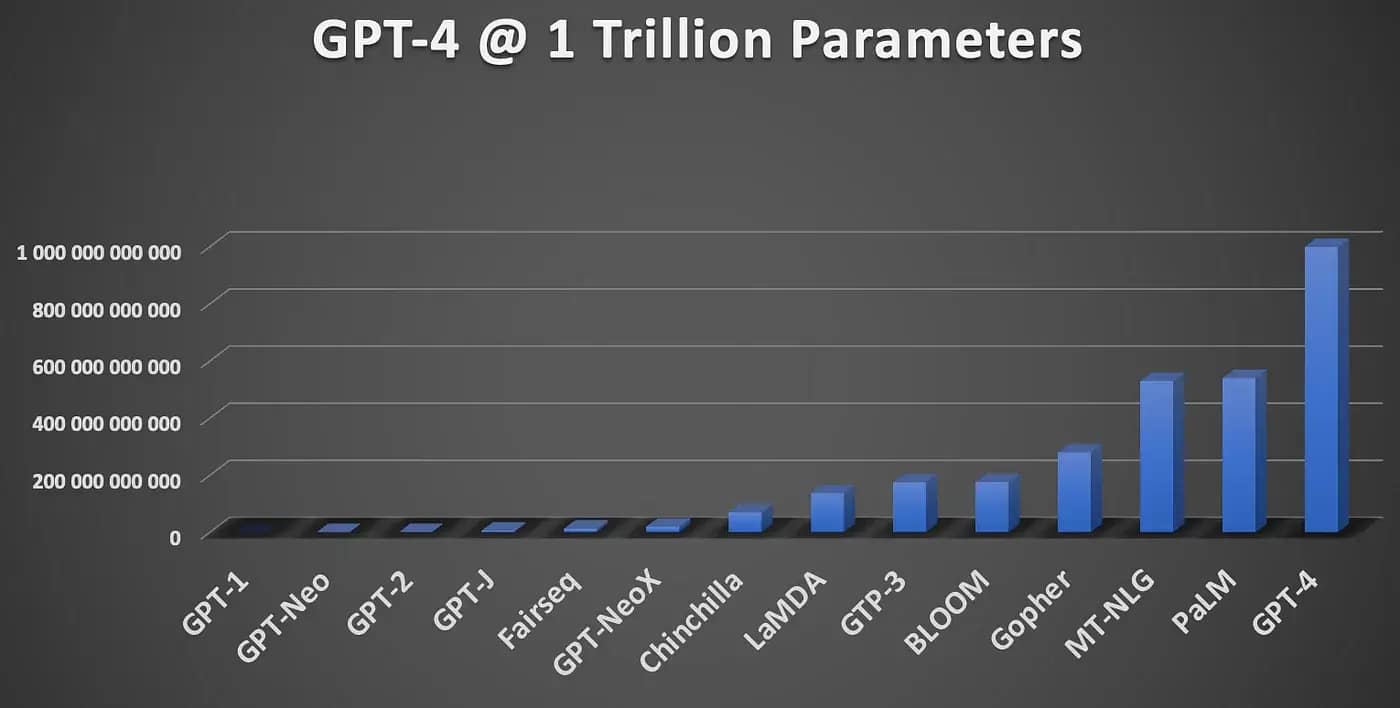
Why are LLMs becoming important to businesses?
- LLMs are revolutionizing the way businesses interact with customers by providing more accurate and personalized responses.
- They enhance customer service by offering instant support through chatbots and virtual assistants, increasing efficiency and customer satisfaction.
- LLMs help businesses analyze vast amounts of data quickly, enabling better decision-making and strategic planning.
- They streamline workflows by automating repetitive tasks like data entry, content generation, and analysis.
- LLMs can assist in content creation, such as writing product descriptions, generating marketing material, and creating reports, saving time and resources.
- Businesses can leverage LLMs for market research, trend analysis, and sentiment tracking to stay ahead of competitors and adapt to changing consumer preferences.
- Implementing LLMs can improve the overall productivity and effectiveness of employees by providing tools for faster research and information retrieval.
- They enable companies to develop and deploy innovative applications and services, driving competitiveness and growth in the market.
- With the ability to understand and generate human-like text, LLMs can be utilized in various industries like legal, healthcare, finance, and e-commerce to optimize operations.
- Businesses that embrace LLM technology early on can gain a competitive edge, enhance customer experiences, and stay ahead in the rapidly evolving digital landscape.
How do large language models work?
Large language models operate by leveraging sophisticated algorithms and vast datasets to generate human-like text. Here is a breakdown of the essential components and processes involved in the functioning of these models:
- Data Collection: Large language models require extensive datasets to learn from. They ingest huge amounts of text from sources like books, articles, and websites to develop an understanding of language patterns.
- Training: Models are trained on high-performance computing systems using techniques like deep learning. During training, the model adjusts its parameters to minimize prediction errors and improve accuracy.
- Tokenization: Text input is broken down into smaller units known as tokens, which can be words, subwords, or characters. This tokenization allows the model to analyze and process text more efficiently.
- Attention Mechanism: Many large language models use an attention mechanism to weigh the importance of different words in a sentence. This mechanism enables the model to focus on relevant information when generating text.
- Generation: When prompted with a specific input or query, the model uses its learned knowledge to predict and generate text that follows from the input. The generation process involves sampling from a probability distribution to produce coherent and contextually relevant text.
- Fine-tuning: In some cases, models are fine-tuned on domain-specific data to improve performance in particular areas. Fine-tuning allows the model to adapt its knowledge to better suit the requirements of a specific task or field.
- Evaluation: Models are evaluated based on various metrics such as perplexity, BLEU score, or human judgment. Evaluation helps assess the model’s performance and identify areas for improvement.
Large language models represent a monumental advancement in natural language processing, with their ability to understand and generate human-like text revolutionizing various fields such as machine translation, content generation, and conversational AI.
![]()
What are large language models used for?
- Large language models are used for natural language processing tasks such as language translation, sentiment analysis, text summarization, and speech recognition.
- These models can generate human-like text for content creation, chatbots, and dialogue systems, enhancing user experience and communication.
- Large language models aid in information retrieval by analyzing and organizing vast amounts of text data to provide relevant search results.
- They assist in text generation for tasks like writing assistance, automated content creation, and code generation, improving productivity and efficiency.
- Large language models play a crucial role in improving accessibility through speech-to-text and text-to-speech applications for individuals with disabilities.
“Large language models are versatile tools with applications in various industries like healthcare for analyzing patient records, finance for sentiment analysis of market trends, and entertainment for personalized content recommendations.”
What are the advantages of large language models?
- Improved Natural Language Understanding: Large language models have the ability to understand context better, leading to more accurate and nuanced responses to queries or prompts.
- Enhanced Text Generation: These models can generate more coherent and contextually relevant text, making them useful for applications such as chatbots, language translation, and content creation.
- Efficiency in Training: Despite requiring substantial computational resources for training, large language models are more efficient compared to traditional models when it comes to generating text-based outputs.
- Better Performance on Diverse Tasks: Due to their extensive pre-training on vast amounts of text data, large language models excel in a wide range of tasks, including text classification, sentiment analysis, and text summarization.
- Transfer Learning Capabilities: Large language models can be fine-tuned on specific tasks with minimal data, allowing for quicker adaptation to new use cases and domains.
- Cost-Effective Solution: While the initial investment in training large language models can be significant, they offer a cost-effective solution for various natural language processing tasks in the long run due to their versatility and high performance.
- Facilitates Innovation: Access to pre-trained large language models encourages innovation, as developers can leverage these models to build new applications and solutions that leverage cutting-edge natural language processing capabilities.
Large language models represent a breakthrough in natural language processing, offering a range of advantages that can significantly benefit various industries and applications.
What are the challenges and limitations of large language models?
- Data Privacy Concerns: Large language models require vast amounts of data to train, which may include sensitive or personal information. This raises concerns about privacy and data security, especially if the models are used for tasks involving confidential data.
- Bias and Fairness Issues: Bias present in the training data can get amplified in large language models, leading to biased outputs. This can perpetuate stereotypes and inequalities, impacting various applications such as hiring processes or content moderation.
- Computational Resources: Training and fine-tuning large language models require significant computational resources, including high-powered GPUs and TPUs. This cost can be a limiting factor for individuals or organizations with restricted resources.
- Ethical Implications: As large language models become more powerful, there are ethical concerns about their potential misuse, such as generating fake content, deepfakes, or spreading misinformation at a scale that is hard to detect or control.
- Interpretability and Explainability: Understanding how large language models arrive at their decisions can be challenging due to their complexity. This lack of interpretability raises questions about accountability and trust in the decision-making process.
- Environmental Impact: The energy consumption associated with training and running large language models is significant. This raises concerns about the environmental impact, especially considering the carbon footprint resulting from the computational power required.
- Fine-tuning for Specific Tasks: While pre-trained models offer a starting point, fine-tuning them for specific tasks or domains can be labor-intensive and may require additional data for effective customization.
- Inference Speed: Despite their impressive capabilities, large language models can be computationally intensive during inference, affecting real-time applications that require quick responses.
- Domain-Specific Knowledge: Large language models might lack specialized domain knowledge, leading to inaccuracies when applied to niche fields or industries that require in-depth expertise.
What are the different types of large language models?
- Autoregressive Models:
- Autoregressive models generate text sequentially, where each word is predicted based on preceding words. Examples include GPT-3 (Generative Pre-trained Transformer 3) developed by OpenAI.
- Transformer Models:
- Transformer models are based on a self-attention mechanism that allows them to consider the entire context when generating text. These models are popular due to their parallel processing capabilities and have been used in models like BERT (Bidirectional Encoder Representations from Transformers) and GPT series.
- BERT (Bidirectional Encoder Representations from Transformers):
- BERT models are trained to understand the bidirectional context of words, significantly improving performance on various natural language processing tasks like sentiment analysis and question answering.
- GPT (Generative Pre-trained Transformer) Models:
- GPT models are solely autoregressive and have been trained on large datasets to generate coherent text. They have been widely used for tasks like language translation and text completion.
- XLNet:
- XLNet is a generalized autoregressive pretraining method that overcomes limitations of traditional autoregressive models by leveraging permuted sequences. It enhances the bidirectional understanding while maintaining autoregressive capabilities.
- T5 (Text-To-Text Transfer Transformer):
- T5 models operate on a text-to-text framework, allowing them to convert varied tasks into a text-to-text format for uniform processing. This versatility has led to proficient performance on multiple NLP tasks.
- Reinforcement Learning Language Models:
- Some large language models incorporate reinforcement learning, where the model learns to generate text through a reward-based system. This approach enables models to refine their outputs iteratively.
Large language models come in various forms, each with distinct architectures and training methodologies tailored to enhance their text generation and comprehension capabilities.
Hugging Face APIs (From “analyticsvidhya.com“)
Let’s look into how Hugging Face APIs can help generate text using LLMs like Bloom, Roberta-base, etc. First, we need to sign up for Hugging Face and copy the token for API access. After signup, hover over to the profile icon on the top right, click on settings, and then Access Tokens.

Example 1: Sentence Completion
Let’s look at how we can use Bloom for sentence completion. The code below uses the hugging face token for API to send an API call with the input text and appropriate parameters for getting the best response.
import requests
from pprint import pprint
API_URL = 'https://api-inference.huggingface.co/models/bigscience/bloomz'
headers = {'Authorization': 'Entertheaccesskeyhere'}
# The Entertheaccesskeyhere is just a placeholder, which can be changed according to the user's access key
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
params = {'max_length': 200, 'top_k': 10, 'temperature': 2.5}
output = query({
'inputs': 'Sherlock Holmes is a',
'parameters': params,
})
print(output)Temperature and top_k values can be modified to get a larger or smaller paragraph while maintaining the relevance of the generated text to the original input text. We get the following output from the code:
[{'generated_text': 'Sherlock Holmes is a private investigator whose cases '
'have inspired several film productions'}]Let’s look at some more examples using other LLMs.
Example 2: Question Answers
We can use the API for the Roberta-base model which can be a source to refer to and reply to. Let’s change the payload to provide some information about myself and ask the model to answer questions based on that.
API_URL = 'https://api-inference.huggingface.co/models/deepset/roberta-base-squad2'
headers = {'Authorization': 'Entertheaccesskeyhere'}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
params = {'max_length': 200, 'top_k': 10, 'temperature': 2.5}
output = query({
'inputs': {
"question": "What's my profession?",
"context": "My name is Suvojit and I am a Senior Data Scientist"
},
'parameters': params
})
pprint(output)The code prints the below output correctly to the question – What is my profession?:
{'answer': 'Senior Data Scientist',
'end': 51,
'score': 0.7751647233963013,
'start': 30}Example 3: Summarization
We can summarize using Large Language Models. Let’s summarize a long text describing large language models using the Bart Large CNN model. We modify the API URL and added the input text below:
API_URL = "https://api-inference.huggingface.co/models/facebook/bart-large-cnn"
headers = {'Authorization': 'Entertheaccesskeyhere'}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
params = {'do_sample': False}
full_text = '''AI applications are summarizing articles, writing stories and
engaging in long conversations — and large language models are doing
the heavy lifting.
A large language model, or LLM, is a deep learning model that can
understand, learn, summarize, translate, predict, and generate text and other
content based on knowledge gained from massive datasets.
Large language models - successful applications of
transformer models. They aren’t just for teaching AIs human languages,
but for understanding proteins, writing software code, and much, much more.
In addition to accelerating natural language processing applications —
like translation, chatbots, and AI assistants — large language models are
used in healthcare, software development, and use cases in many other fields.'''
output = query({
'inputs': full_text,
'parameters': params
})
print(output)The output will print the summarized text about LLMs:
[{'summary_text': 'Large language models - most successful '
'applications of transformer models. They aren’t just for '
'teaching AIs human languages, but for understanding '
'proteins, writing software code, and much, much more. They '
'are used in healthcare, software development and use cases '
'in many other fields.'}]These were some of the examples of using Hugging Face API for common large language models.
The Future of Large Language Models
Large language models have revolutionized various industries and are continuously evolving to offer even more impressive capabilities in the future. Here are some key aspects to consider when looking at the future of large language models:
- Improved Accuracy: As research and development in the field of large language models progress, we can expect to see a continuous improvement in their accuracy. This will enable these models to provide more reliable and precise results across different tasks and domains.
- Specialized Models: Future advancements will likely lead to the creation of more specialized language models tailored to specific industries or use cases. These models will be designed to excel in particular tasks, allowing organizations to leverage them for targeted applications.
- Multilingual Capabilities: With the increasing demand for multilingual support, large language models of the future are likely to be more proficient in understanding and generating content in multiple languages. This will further enhance their versatility and usability on a global scale.
- Contextual Understanding: Future models will focus on enhancing their contextual understanding abilities, enabling them to grasp nuances, sentiment, and tone in a more sophisticated manner. This improvement will make large language models even more effective in natural language processing tasks.
- Ethical Considerations: As large language models become more prevalent, there will be a growing emphasis on ethical considerations surrounding their use. Future developments will likely prioritize addressing concerns related to bias, privacy, and responsible AI deployment.
Large language models hold the potential to transform the way we interact with technology, communicate with each other, and process information. By keeping an eye on these future trends, organizations can stay ahead of the curve and harness the full power of these remarkable advancements.




